项目地址
https://github.com/GanjinZero/Tenpai_prediction
项目背景
日本麻将是一种最强调防守的麻将,它比其他的麻将更注重不要点炮(也就是放铳)。雀魂最近比较流行,所以我又重新开始玩日麻(以前在MJ和天凤都打过一点)。我也比较菜,才打到雀士三。一个经常遇到的场景时,当有人立直(门清宣告听牌)的时候,当我选择弃胡时,我想知道应该打出什么样的牌才不会点炮。这就是在这个项目中研究的问题:当他家率先立直时,他家可能的听牌有哪些。这个问题可以看成是一个文本分类问题来考虑,将前面已经打过的牌当作文本,听牌考虑成文本最终的分类。当然这还是和文本分类问题不太一样的,因为对于某一个文本一般是固定一个分类(比如情感分类中的积极或者消极);而对于麻将而言首先一次听牌可以听好几种牌(纯正九莲宝灯!)、其次同样的舍牌可能听的牌完全不同。
在这里推荐一本书《科学するマジャン》,可以在苹果的图书商店下载到。这里有利用概率论计算的麻将打法和一些关于麻将的数值模拟结果。本项目也是在阅读该书中产生的想法。

1 | ロン!断幺九!30符1番,1000点! |
数据准备
牌谱收集
最初是在《科学する麻雀》中看到了该书作者とつげき東北的个人主页,然后在这面找到他收集的一些在东风庄这个平台上的一些牌谱。

一共收集有万份左右的牌谱。
一份牌谱的示例如下
1 | 東2局 0本場(リーチ0) YZKTR 3000 松戸の俊 -1500 菌太郎 -1000 シャモア -500 |
这里记录了对局信息,胡牌的番型和各家起手牌、宝牌、每家每一轮的摸牌、切牌和鸣牌。这些牌谱的具体信息会在下文的牌谱准备中详细介绍。4R代表南家立直,那么对于东、西、北家都需要预测南家可能的听牌。因为各家的起手牌不同,摸到的牌也不同,所以对于南家的听牌有不同的估计(在德扑中叫做阻隔牌)。三家由于有不同的起手信息,所以可以生成三份训练数据。例如对于北家而言,可以只留下北家可以知道的信息作为训练用的x,而将南家的真实听牌作为训练用的y。
数据增强
只用这些牌谱数据看起来还有些不够,训练出的结果不是很理想。考虑可以这样生成一些假的牌谱。将中、发、白以某种顺序置换;将饼、万、索以某种顺序置换;将123456789变成987654321。这样的变换不能保证是完全合理的。一个原因是绿一色导致索和饼、万并不是完全等价的,但考虑到绿一色出现的概率如此的低就不管了。另一个原因是宝牌的问题,比如原来的宝牌指示牌是1m,宝牌是2m。如果进行了123456789变成987654321,宝牌就会变成8m;这时宝牌指示牌并不能变成9m,而变成了7m。这两个问题不能很好解决,但为了获得更多的牌谱,还是进行了这几种置换。中发白的置换共6种,饼万索的置换共6种,数字颠倒共2种(颠倒或者不颠倒),一共6*6*2=72种变换方式。对每一份牌谱,我们随机的选择k=7种变换作为增强的数据。(考虑到内存大小,k不要太大)
将牌谱编码
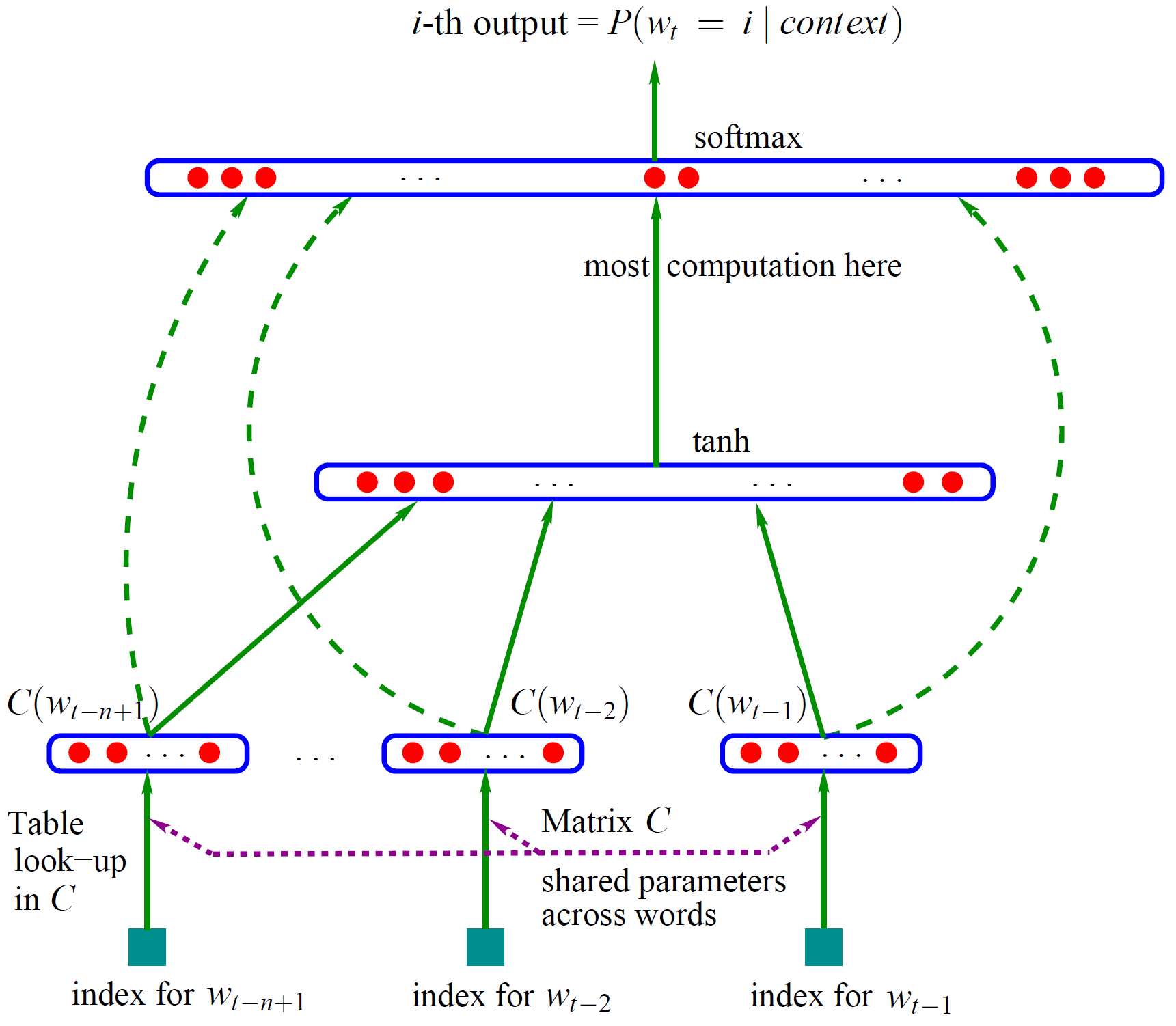
我们将每一次摸牌,鸣牌或者打牌都定义为一个action,然后将这个action嵌入到一个52维向量中。这个向量描述了这个动作是谁执行的(东西南北家),是进行了什么动作(摸牌、切牌、吃碰杠、立直),是和哪一张牌进行了交互,交互牌是否是自风、场风、宝牌这些信息。具体的编码方式可以看/src/haifu_parser.py中的action_to_vector(action, player, chanfon, jikaze, dora_list)函数。
模型训练
模型使用了双层LSTM网络连接34维的Softmax层进行预测(麻将一共34张不同的牌)。损失函数为交叉熵。在两块1080Ti的显卡下训练70个epoch得到了预训练的模型,大约需要训练2个小时。具体的模型可以参照/src/neural_network.py中的结构。
进行预测
预备工作
需要有可以编译Python3的环境。在终端中输入1
$ git clone https://github.com/GanjinZero/Tenpai_prediction.git
下载该项目。在终端中输入1
$ pip install -r requirements.txt
安装依赖。
牌谱准备
预训练好的模型保存在model/tenpai.model。我们需要将牌谱设置为data/test.txt中的格式,并保存到data/test.txt中:1
2
3
4
5
6
7
8
9
10東2局 0本場(リーチ0)
123
[1西]
[2北]1m5m6m7m4p6p1s5s7s東白白中
[3東]
[4南]
[表ドラ]西 [裏ドラ]北
* 3D9s 4d9m 1d北 2G4m 2d1s 3D6p 4d1m
* 1d南 2G2s 2d1m 3D6s 4D2s 1C3s4s 1d8m 2C6m7m 2d2s
* 3D3s 4d9p 4R 1G3s 1d9p
- 第一行填写东x局(或者南x局),后面的本场、立直棒、点棒信息都不是必要的。
- 第二行填写符数、翻数、番形,可以留空行,但不能把这行都删了。
第三-六行填写四家起手牌,可以只填自家牌,其他留空。其中m代表万,p代表饼,s代表索;“東南西北中発白”请使用日语汉字。比如:
1
2
3
4[1西]
[2北]1m5m6m7m4p6p1s5s7s東白白中
[3東]
[4南]第七行填写宝牌和里宝牌,里宝牌可以不填。注意是宝牌,不是宝牌指示牌!
- 第八行起填写这局牌的行进过程。每一行以*开始,每一个行动和行动之间有一个空格。比如第一行的动作3D9s可以翻译为东家摸切9s,4d9m可以翻译为3家切掉9m。只需要记录自家的摸牌动作(在这里就是2G,因为其他家摸到的牌你是看不见的,就算输入了模型也会忽略其他家的摸牌数据)完整的动作对应表见下表:
| 字符 | 含义 | 用法示例 |
|---|---|---|
| G | 自摸(不是自摸和) | 1G1m |
| d | 切牌 | 1d2s |
| D | 摸切 | 1D1m |
| N | 碰 | 1N |
| C | 吃 | 1C1s3s(1s3s是玩家1自己的牌) |
| K | 杠 | 1K1s |
| R | 立直 | 1R |
| A | 胡牌 | 1A |
data/test.txt中可以保存多个牌谱,请在牌谱和牌谱之间用空行分隔。
P.S. 如果可以直接获取到文字格式的天凤或者雀魂牌谱,可以编写一个牌谱的自动encoder,就不需要上述这么麻烦了。
开始预测
在src文件夹下,使用如下的命令进行预测
1 | $ python predict.py |
就可以看到类似如下的预测结果
1 | Richi player tenpai: ['3m', '6m', '9m'] |
其他
欢迎提供更多的牌谱和咖啡给作者!联系作者:
Github - https://github.com/GanjinZero/
Email - yuanz17@mails.tsinghua.edu.cn